ISUCON 10 予選参加記
ISUCON とは Iikanji ni Speed Up CONtest です。
≒ウェブアプリの高速化を競うコンテストです。
大学時代の友人 (ugwis, altescy, kob) で参加しました。
競技前
コンテストが始まる前までに準備したことは主に以下三点です。
- APM選定(opentelemetry + jaegerになりました)
- 役割分担決め(マニュアル読み、opentelemetry 入れる係、メトリクスツール導入係)
- opentelemetry + jaeger, prometheus + grafana の環境用意(kob)
opentelemetry 何もわからなかったので、前日に使い方などを確認しました。
競技中 (12:20 ~ 21:00)
13:18 初期ベンチ
=> スコア:496
- kataribe 導入
- OpenTelemetry 導入
- スロクエリログ有効化
- node_exporter 導入
15:01 インデックス追加 (altescy)
=> スコア:604
- node_exporter 用ポートフォワーディング
17:58 searchEstateNazotte の改善 (ugwis)
ISUUMO の「なぞって検索」は N+1 で実装されており、判定もポリゴンで判定していたため、1 クエリ化。
geometry 型のカラムを追加しようと考えていたのですが、カラム追加せずとも BoundingBox の条件を追加すれば早くなるのではと言うお告げを受け、試してみると本当に早くなって kataribe の top に出なくなったため geometry のカラムは入れませんでした。 => スコア: 775
19:09 DB を別サーバに移行(altescy)
mysqld の CPU 負荷が大きかったため、どうせ DB も分けるということで、App と DB を別々のサーバで起動するように変更。 => スコア: 819
20:14 /api/estate/[id] のキャッシュを返す(kob)
/api/estate/[id] に対する GET リクエストがかなり多く、kataribe 上でも遅いことがわかったため、estate に対する変更 (UPDATE) がないことを確認し、キャッシュを追加。 => スコア: 1345
22:05 searchEstate の range 検索の高速化(altescy)
DB 上では物件のドアの高さ、幅、賃料が数値で格納されていますが、検索時はレンジ ID (100~200 or 200~300) のように指定するだけなので、SQL で都度検索時に rent < 100 & rent > 200 というように条件してするのではなく、rangeID = 1 のように検索できればインデックスを生かせて早く検索ができそうというアイデア。
alt 君が頑張って変更してくれて、終了間際変更完了はしたものの、ベンチマークが完了せず結果がわからなかったため、最終追試でこの改善結果が反映され、最終スコアが上昇しました。 => スコア: 1715 (47位)
ベンチマーク側のバグかどうかに関しては不明なため、最終追試がスコアとして判定されたかは不明ですが効果のある改善だったことが分かってよかったです。
感想
今回は次にやるべきことがある程度明確であったので、虚無の時間を過ごすことが少ない印象でした。 ちなみに、運営側の最大スコアは 8000 点だったようで、頑張ればそこまで上がるらしいです。 http://isucon.net/archives/55025156.html
DB 分割や、降順ソートの問題は気付いておらず(ソートが効いてなさそうだよねという話はあった)、もう一つ改善し 2000 点台であれば本選へ進めた可能性もあるのかなといった水準でした。
(各々の感想は各々書いてくれると信じますが!)個人的にはコードを書くことやパフォーマンスチューニングを行う機会がほとんどないので、仕事であまり触れない以上事前練習や自分のプロダクトを増やしていくのが今後の自分の課題になりそうです。
6桁の数字を読み取りたい
この記事は、kstm Advent Calendar 13日目の記事として書かれました。 qiita.com
ある時ふと7セグメントのLCDを読み取る必要があるかもしれない。それは、デジタル電流計かもしれないし、分解してはいけないファンヒーターの温度計かもしれない。

単純に考えれば、Webカメラを固定し、光源を用意し、座標を指定してOCRすればよいと考える。
しかしそのような手間はきっとソフトウェアで対処することができる
物体検出
カメラや物体の位置がずれてもカメラの中に映っていれば、認識してほしいと思う。パターンマッチングなどいろいろな方法で7セグメントLCDを読み取ることができるが、今回の場合は7セグメントLCDの周りの物体を検出し、LCDの場所を推定しようと思う。
特徴点抽出
画像のような大きいデータはできるだけその画像の特徴を表したベクトルに変換すると良い。変換することを特徴点抽出といい、SIFTやSURFなどはそれらを抽出するためのアルゴリズムである。
特徴点は多ければ良いというものではなく、後述するマッチングを行う際に特徴点に比例して計算量が増えるため、画像自体を少ない数で画像の特徴を表す特徴点を取るアルゴリズムが良い。今回はSIFT,SURFが特許の関係があるため、A-KAZE特徴量を想定する。

↑小さく表示されている円が特徴点
A-KAZE特徴量抽出アルゴリズムは前身のKAZE(風)を高速化したもので、他のアルゴリズムに比べスケール変化耐性、回転耐性、輝度変化耐性、Blur耐性、スピードどれも精度がよく、またSIFTやSURFは特許の問題があるため代用としてAKAZEがよく使われています。
SIFT,SURF,ORBなど他のアルゴリズムと精度を比較した記事があります。
AKAZE特徴量の紹介と他特徴量との比較
特徴点マッチング
Webカメラを固定せずに7セグメントを読み取るためには画像の中に物体がどこにあるかを判定する必要がある。あらかじめ物体の写真を撮って、Webカメラから送られてくる画像と特徴点マッチングを行うと、物体がどこに映っているのかを見つけることができる。

二つの画像の特徴点をそれぞれどの点なのか対を生成する(マッチング)ことにより、画像のスケール、傾き、反転などに影響されることなく物体を検出することができる。
特徴点マッチングのアルゴリズムは総当たり(ブルートフォース)、高速最近傍探索(FLANN)などがあり計算量は違うが、なににせよ前述した特徴点が少なく効率よく特徴を表しているほど射影変換がうまく行く。
射影変換
特徴点マッチングを終えたあとは、ホモグラフィ変換(射影変換)により対象とする物体が画像のどこにあるかを変換する。
画像は変換したあと、物体があると認識されている部分を矩形で表示している。

7-segの読み取り
矩形検出
物体の位置がわかったため、物体の中のLCDの位置を矩形検出する。
LCDはほぼ長方形の形をしていることが多いため、findContours()で輪郭を検出することでLCDの場所を見つけることができる。

ヒストグラム平坦化
ここまでで、LCDの位置や傾きなどの問題に対処することができたが、輝度の問題が解消できない。光源が変わってもある程度読み取るためには光源が変わっても輝度値が大きく変化しないようにすることが重要である。

引用: OpenCVチュートリアル - ヒストグラム その2: ヒストグラム平坦化
二値化
LCDで背景の部分と数字が表示されている部分をくっきりと分けるほどOCRの精度が上がる。背景を白、文字を黒と二つの色だけに分けるのを二値化と呼ぶ。二値化するときに問題なのは、単純な閾値だけで分ける場合閾値を指定しなければいけない、光源によって全体的にグラデーションのかかった画像はうまく二値化することができない。
局所的な二値化を適応閾値(Adaptive Theshold)で行うことで全体的なグラデーションによらずうまく二値化することができる

クロージング処理
二値化だけではセグメントの周囲にごま塩ノイズができるため、これがOCRの認識の邪魔をしていた。
クロージング処理は膨張した後に縮小処理をすることによって画像内の小さな黒い点を除去できる
OpenCVではmorphologyExでcv2.MORPH_CLOSEを指定することによってクロージング処理ができる
処理前
処理後

モルフォロジー変換
SSOCR
LCD部分を適応閾値により二値化し、OCRで数字を認識する。TesseractなどいろんなOCRがあるが、今回のように7-segのみを読み取る場合はssocr(Seven Segment Optical Character Recognition)がオススメである。

https://www.unix-ag.uni-kl.de/~auerswal/ssocr/
参考文献
「特徴点のマッチングとHomographyによる物体検出」
http://labs.eecs.tottori-u.ac.jp/sd/Member/oyamada/OpenCV/html/py_tutorials/py_feature2d/py_feature_homography/py_feature_homography.html
「Fast Explicit Diffusion for Accelerated Features in Nonlinear Scale Spaces」 http://www.bmva.org/bmvc/2013/Papers/paper0013/paper0013.pdf
プログラミングとkstmの話
この記事はkstm Advent Calendar 23日目です。
昨今、プログラミング教育の重要性が高まっているそうです。本当かどうかはさておき、プログラミングってどういうふうに教えるのが最適なのでしょうか。私はどちらかというと教えられたというよりは好きなことやってたらこうなってただけなので、プログラミングを教えることにはそれほど興味はありません。
プログラミングとは
厳密な定義というよりは私の主観的なイメージを書きます。プログラミング言語と呼ばれるようにプログラムは一種の言葉だと思います。これに異論を唱える人はそこまで多くないと思います。なぜなら一つの目的を遂行するためのコードはいろんな書き方が出来るからです。最近の高級言語ではコンパイラの完成度が高かったりライブラリが豊富なこともあり、この言語でないと作れないという場面がすごく少ないです。(組み込みは除く)そのため、どの言語を使うかというところから始まり、どのライブラリを使うか人間の可読性を優先させるかコードの実行スピードを優先させるかによって人の趣向が表れます。AtCoderというプログラミングコンテストサイトの他のユーザの提出を見れば感じると思いますが、同じことをするプログラムでもコードが全く一緒になることはあまりありません。これだけの多様性を持っているということはつまり、目的や状況や好みに合わせて単語と単語をうまく繋ぎかえる論理的な能力が必要なのだと思います。プログラミングが言語であれば言葉を組み立てる論理的な能力も必要になります。論理的な能力が高ければ言葉遊びができるように、プログラミングでも言葉遊びのようなことが出来ます。面白い例としては国際難読化Cコードコンテスト(https://ja.wikipedia.org/wiki/IOCCC)のようにコードの豊かな表現力を競うコンテスもあります。
プログラミング教育
では、プログラミングはどのように教えるべきなのでしょうか。プログラミング教育に関してはいろんな意見があると思いますが、僕としては義務教育としてのプログラミングは教えるのが難しい教科になるのではないかと思っています。 義務教育ではありませんでしたが、一応僕は高校・大学と情報系の学科にいます。今は大学2年なので4年と少しの間、情報に関して教えられているはずです。その中で高校の先生はC言語やアルゴリズムについて丁寧に教えてくださり私はその授業はとても楽しかったのですが、周りの生徒はそうでもなかったようでした。クラス全体でC言語をしっかり理解していそうだと思ったのは5分の1くらいで、その中でプログラミングが好きだといった生徒はその5分の1くらいでした。勉強に得意不得意があるのは仕方がないことなのですが、プログラミングがある程度できると思われる人でさえ、プログラミングが好きだと答える人は少ないイメージでした。これにはいろんな理由があると思いますが、プログラミング故の問題があると思います。まず、先に述べたようにプログラミング言語は一種の言葉であると思います。であるならば、できるだけ単語や文法を覚える必要があります。しかし、プログラミング言語における単語や文法といったものはそこまで多くありません。少なくとも英語よりは単純で覚えることも少ないと思っています。では、なぜとっつきにくいのかというと、プログラミング言語の基礎的な知識はそれぞれ密接に関係しているのが原因だと思います。そのため、あるところで理解が浅いてしまうとそれに関するものも理解できないといったことが起きます。言語の入門として教えられる制御構文や演算子などは基礎中の基礎であり、それをすこしても理解が不十分だと後々に影響が出てくるのは明らかです。(しかも一年ぐらいでC言語を教えるのは結構きつい)しかし僕が受けてきたプログラミング教育では、教えたことはすべて理解し覚えているという前提のもとに成り立っているように思います。実際には授業のみでそこまでの理解を得られる人はごく少数で理解を得ている人のほとんどは授業以外でもプログラミングに触れていたり数学などから近い概念を得ている場合が多いと思います。しかし、自分で勉強することを前提としたものを教育と呼んでいいのでしょうか。確かに大学の単位の定義には、講義の時間と予習の時間を含め何時間以上を一単位と決めているようですが、本当にプログラマーをたくさん育てたいと思うのであれば知識よりもプログラミングのおもしろさを伝えるだけでいいのではないかと僕は思っています。むしろ教えすぎることはその知識を初めて得たときの感動を奪っているような気がしてならないのです。ただただ、Hello,worldを表示するのに対してそれをただ文字を表示されていると思うか自分がコンピュータを支配する一歩を踏み出したと思うかは人それぞれだと思います。それがプログラマーの素質だと僕は考えています。
本題
ここまでいろいろ教育がどうのこうの書きましたが、ぶっちゃけ教育なんてどうでもいいです。なぜなら、教える側も教わる側も知識さえあれば良いと思っているからです。しかし大事なのは知識よりも情熱(passion)です。よくプログラミングの何が楽しいか分からないという話を聞きますが、教えられる気でいる以上はプログラミングの楽しさはそこまで感じられないのではないかと考えています。食事に例えていうと、お腹がすいた時に自分からご飯を選んで食べると思いますが、これが誰かによってメニューを決められてしまうとすこしご飯の楽しさが減ってしまいませんか?今日はカレーを食べたい気分なのに寿司を食べなきゃいけないとか。そういうことがプログラミングの教育にも起きていると思うのです。「俺が欲しいのはポインタの知識じゃなくてゲームの作り方なんだ!」っていう人も多いんじゃないですかね。プログラミングの応用分野は多岐に渡るのですべてを教えるのは不可能です。なので教えるのは基礎的な構造とかコンピュータはどうやって動いてるかとかそういう話になりがちです。でも学生の情熱はそこに向いていなかったりするわけです。じゃあどうしようか。僕は何も教えないのが最適だと思っています。気になる食べ物を選んでもらって食べて自分に合うか合わないかを考えてもらうように、自分の作りたいものを選んでもらって作ってもらって、知識はその過程で得られれば良いと思います。それじゃ体系的に知識が得られないじゃないかという人も出てくると思いますが、全体的な知識が足りないと感じれば大学のような講義でもいいですし、しっかりと学びたいのであればオンライン講座(http://dotinstall.com/)等を受ければいいんじゃないでしょうか。
kstmとは
kstmはものづくりサークルです。主に情報工学科の学生で構成されていてプログラミングやネットワークの構築などを実際にやっています。名目としてはものづくりサークルなのでコンピュータの技術に限らず料理を作ったり肉体ビルドしていたりします。 現在は活動時間が決まっておらず、授業終わりに集まっているだけですが基本的に何をしていてもいいサークルなので各々授業の課題やプログラミングしていたりスポーツしていたりします。
kstmのよいところ
kstmは放任主義です。一応顧問の先生もいますが、何かをやれと命令されることはまずありません。完全に放任主義であるため、各々好きなことをやっています。このサークルが成り立っているのは好きで勝手にコンテスト出て賞を取ってきたりするからだと思います。好きに過ごしていていい空間というのは、ある程度自分に対して厳しくある必要もありますが、前述したような情熱を失わせるような何かはありません。(あえて言えば煽りあいの結果情熱を失わせている可能性は無くはない)この環境が各々によって良いかどうかはわかりませんが、自分にとってはすごくよい空間です。少なくとも、kstmに入るまでは人とコンピュータの話で盛り上がれることはありませんでした。一人で知識をつけて面白い技術を見つけてもその感動とかを伝える先はTwitter以外になく、とても辛かったです。それに比べるとすごくいい空間だなと思います。
保険
一応ここまでの文章は完全に自分の見解です。というか本当は他の人にレビューしてもらってから公開しようと思っていたのですが完成せずに期日が来てしまいました。何が言いたかったかというと、kstmはあう人によってはすごく良い環境だということを伝えたかっただけです。
さいごに
おそらくアドベントカレンダーで僕が書く番はこれが最後だと思うので今回のアドベントカレンダーについての感想も書いておきます。19日目togaerrorさんの記事にもあるように、僕が今年のアドベントカレンダーの責任を投げられた人でした。アドベントカレンダーの存在は元から知っていましたが、団体としてアドベントカレンダーを作る文化があるというのは知らなかったのでどうなるのか最初は不安でした。そもそもkstm Advent Calendarって何を書けばいいのか分からず、(技術系のネタばっかり書けばよいのかkstmを絡めて書くべきなのか)日数が経つごとに目的が明確になっていったような気がします。少なくとも僕はこのアドベントカレンダーは広報の一種だと思っている。僕の当初の予想では、一週間ぐらいで誰も登録しなくなり挫折するだろうと思っていたのですが、なんだかんだで続いてしまい(しかも予想よりまともな記事が多い)少し驚いているところです。この記事群が誰かのためになるのかどうかと言われると疑問ですが、信州大学の工学部にkstmというサークルがあって、今の時代でもこういうことを好き勝手にやってしまう人達がいるということが伝わば良いなと思います。また、サークルのメンバーもいつでも募集しておりますので興味のある方はご連絡いただければと思います。
競プロ問題推薦システムの話
この記事はkstm Advent Calendar 5日目です。
目的
プログラミングやアルゴリズムを勉強しようと思って競プロのジャッジシステムを使う方は多いと思います。
しかし、競技プログラミングは問題が多種多様だったり、難易度を決めるのがとても難しいです。効率よく学習するために、その人に合わせたプログラミングの問題を推薦するシステムがあれば学習者の負担やモチベーションの低下を防ぐことが出来るのではないかと考えました。
そこで作ったのがAtCoder-Recommendationです。
http://sandbox.ugwis.net/recommend/
これは、AtCoder上で解いた問題傾向と近いユーザーを探し、自分に対して解いてない問題を推薦するサービスです。
協調フィルタリング
他のユーザーとの距離を計算し、推薦するアルゴリズムを強調フィルタリングと言います。
推薦アルゴリズムには二種類の分類があり、内容ベースとユーザーベースの物があります。
内容ベースはアイテムの属性を数値(またはベクトル)で表現し、アイテム間の距離を計算することで推薦する手法です。
一方、ユーザーベースの推薦システムはユーザー間の距離を計算し、その距離から似たような傾向のユーザを探すことができます。
強調フィルタリングはユーザベースの推薦アルゴリズムで、実際の推薦する内容に関わらず統計的なデータをもとに推薦します。
AtCoder-Recommendation
AtCoder-Recommendationでも協調フィルタリングを使用して推薦しています。
まず初めに推薦したいユーザに近いユーザを探すためにジャッカード指数という式を計算し、ユーザー間の距離を計算します。
推薦するユーザとその他のユーザとの距離を計算すると、自分に近いユーザが解いていて自分が解いていない問題が分かります。
ユーザ間の距離をコストとして問題に重みづけをしていって、コストが一番小さいものがそのユーザに対して推薦するべき問題であることが分かります。
実際にコードとして書いてみるとそこまで時間はかからず、計算もそこまで複雑ではありません。
課題
推薦精度
今回作成したAtCoder-Recommendationに関わらず協調フィルタリングは内容を一切考慮しないため、推薦の精度に関しては内容ベースのものには劣ります。今回の場合は、「自分に近い人が解いていて自分が解いていない問題は自分にとっては簡単な問題である」という仮定のもとに推薦しています。しかし、AtCoderは基本的にオンラインコンテストとして時間を決めて問題を出題しているため、例えばそのときはたまたまコンテストに出られなかったので解いていないという場合も考えられるため、推薦する対象として適切である とは言えません。Aizu Online Judgeの方がまだ推薦する対象としては良いかもしれません。
推薦結果の扱い方
今回のシステムでは推薦結果をEasy ,Medium, Hardの三種類に分けて推薦しています。自分にとって簡単な問題と、中くらい、ちょっと難しめという難易度になればよいなと考えていますが、実際にはすこし意味合いの違う推薦結果が出ています。推薦している部分のソースコードを読めばわかりますが、Easyはコストが大きい問題、Mediumは一番コストが大きい問題の半分のコストの問題、Hardは四分の一のコストの問題を順番に表示しています。
しかし、問題のコストというのは問題の難しさではなく、自分に近い人が良く解いているかどうかしか現れていません。相関関係はあると思いますが、自分があまり解いていない問題が難しい問題かどうかはまた別問題です。
Easy, Medium, Hardというのはニュアンスとしては間違っていて、Challenge Problemという風に書いた方が伝わるかもしれません。
今後の期待
今回作った推薦システムはユーザベースであったため、内容を一切考慮せずに推薦しました。統計的な処理だけでもここまでの精度が出せるのはすごいことだと思いますが、実際に使うにはもう少しユーザに対して親切な推薦が出来ればもっと良くなると思います。 以下は競プロ問題推薦システムの改善アイデアです。
対話形式で推薦
少し昔にネットで流行ったAkinatorという質問の回答を元に回答者の想像している物(または人物)を推定するというサービスがあります。 競プロ問題推薦システムでも同じようなシステムを作ることが出来るかもしれません。今日はフローの問題を解いてみたい気分だとか、簡単な問題を解きたいとかそういうのが対話形式で見つけられるかもしれません。
問題グラフ
推薦システムではありませんが、それぞれの問題の位置関係を二次元平面状で表せると面白いなと思います。同じ傾向の問題を近い位置にするには問題をベクトル化する必要があります。ぱっと思いつくのがTF-IDFのような計算を用いてそれぞれの問題間の距離を推定し、空間にプロットすると同じ傾向の問題は近くに表示されるのではないかという推測です。プログラミング言語もある意味では言葉であるので自然言語処理で用いている方法と同じやり方で出来る事があるかもしれません。二次元平面状でプロットすることが出来るようになると、k-Means等のクラスタリングアルゴリズムを使用することが出来るようになるので、コンピュータが問題の分類をすることが出来るようになるかもしれません。
コーヒーの話
この記事はkstm Advent Calendar 5日目です。
最近kstmの部屋にコーヒー豆とドリッパーを置いてみたのですが、思ったより抽出して飲んでくれる人が多いので、自分の知っているコーヒーの話でもします。 こんな記事を書くのもおこがましいぐらい素人なので足りない部分については許してください。間違っている部分があればコメントください。
コーヒーの種類
コーヒーには大きく二つ
ドリップコーヒー
逆三角錐みたいな形をした抽出器具(ドリッパー)に形の合うフィルターをつけて挽いた豆を入れます。 上からお湯を注いで抽出したものをドリップコーヒーと言います。 ドリップは英語で雫という意味です。 基本的にはドリッパーの下にコーヒーサーバーを置いて滴り落ちるコーヒーを集めておきます。
フィルターにも種類があり、三角錐・台形・ステンレスフィルターがあります。

エスプレッソ
エスプレッソはドリップコーヒーのようにお湯を注ぐのではなくコーヒーの粉に蒸気圧をかけてコーヒーを抽出します。ドリップコーヒーよりも濃く抽出されます。 エスプレッソに使われる豆は基本的には深煎りで、抽出された液体は三層に分かれます。

上から順番にクレマ・ボディ・アロマ(ハート)と呼びます。
コーヒーのすゝめ
コーヒーと言えばインスタントコーヒーを飲んでいる方が多いと思いますが、僕は最近自分でコーヒーを入れて飲むようになりました。 インスタントコーヒーと、自分でコーヒーを入れるのはちょっと違います。実はインスタントコーヒーと、コーヒーショップで売っている豆は種類が違います。インスタントコーヒーはロブスタ種という比較的栽培がしやすい豆を使用しています。安価な分風味は泥臭く感じる人もいるそうです。一方でコーヒーの専門店でよく扱っているのはアラビカ種というロブスタ種より栽培がしにくく、その分豊かな風味を持っています。アラビカ種は栽培できる気候が限られていたり害虫に弱いのでロブスタ種より高価です。実はロブスタ種の方がアラビカ種よりカフェインの量は2倍含まれています。つまり一般的なインスタントコーヒーの方がカフェインの量は多くなります。
Hyper Text Coffee Pot Control Protocol(RFC2324)
プログラマーはコーヒーが大好きなので、コーヒーを入れるためのプロトコルもあります。
http://www.chibutsu.org/iorin/rfc/rfc2324.txt
HTTPの拡張として作られたので通知が受け取れないなどの問題があるようです。
HTCPCPを使わずコーヒーサーバを制御するシステムを作った人がいます。mixiの開発ブログを読むと分かり易いと思います。
コーヒーの淹れたてを飲みたいが、コーヒーメーカーの前まで行って抽出を待つのがもったいないといってコーヒーメーカーを遠隔操作出来るようにして、移動時間を測定するような研究者もいるとかいないとか。
ただただコーヒーを入れるためにここまでするのはエンジニア魂ですよね
あとがき
コーヒーは奥が深いのでもっと知識を付けて来年のアドベントカレンダーに書きたいと思います。
GIS入門
この記事はkstm Advent Calendar 2016の3日目の記事です。
GIS系と呼ばれる分野があり、結構奥が深いと思ったのでその話をしたいと思います。
プログラマーがGISに関わりのある仕事に就く割合はそんなに多くはないと思いますが、僕がバイトを始めてGISに関することを知るのに結構苦労して、分からずに何度も書き直した記憶があるのでこれから始めようと思う人に向けて記事を書きます。
地理情報システム(GIS)とは
GISとは、地理情報システム(Geographic Information Systems)の略称で、文字や数字、画像などを地図と結びつけて、コンピュータ上に再現し、位置や場所からさまざまな情報を統合したり、分析したり、分かりやすく地図表現したりすることができる仕組みであり、行政や市民生活やビジネスの現場で幅広く利用することが可能である。
http://www.gis.jacic.or.jp/gis/gakushu/whatisgis/whatisgis1.html
国土地理院などの機関が公的なデータとして行政区域や河川、道路などの情報を公開しています。 これらのデータを使って便利なアプリケーションなどを作ろうというのが目的です。
この記事では、ブラウザで地図を表示する時に必要な知識について焦点を当てて書きたいと思います。
地図タイル
ブラウザ上で地図を表示する時に重要なのが、地図タイルです。Google Mapなどを開いた時に、読み込みがある一定の正方形区切りに行われていることに気づく人もいるかもしれません。
実はほとんどの地図表示ライブラリでは、正方形の画像をつなぎ合わせて地球全体の地図を表示しています。(256x256ピクセルとか)それぞれ拡大率に応じて画像が用意されています。
サーバー側では地図画像は分割されていて、クライアントの動きに応じて表示に必要な画像だけをサーバーにリクエストしています。
どんなURLでリクエストを送るかとかもある程度基準があります。
地理院の地図タイルの場合は
https://cyberjapandata.gsi.go.jp/xyz/std/{z}/{x}/{y}.png
地図タイルサーバは基本的に{z}/{x}/{y}の形式が多いです。
たまに{x}/{y}/{z}もあります。
zが倍率でxやyが地球を何分割かした時の左上(左下)からの番号です。
地図タイルにも分類があり、ラスタ画像とベクタ画像があります。
ラスタタイル
ラスタタイルは通常の画像形式(pngとか)でサーバは正方形区切りの画像を返します。
例えば北海道の一部を表示する地理院地図のラスタタイルを以下に示します。
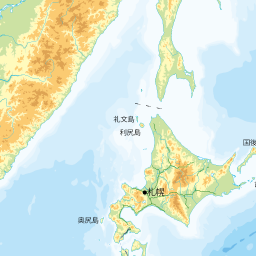
http://cyberjapandata.gsi.go.jp/xyz/std/5/28/11.png
ベクタタイル
ラスタタイルがあればベクタタイルもあります。
ある正方形の区切りの中のオブジェクト(点・線・図形)をサーバが返してブラウザ上で表示することができます。
主に使われるのはGeoJSONという形式で、地図表示ライブラリにはGeoJSONを勝手に解釈して表示してくれるものもあります。
GeoJSONは名前の通りGeometry(Geography)の情報を載せたJSONです。下に使用とサンプルを示します。
http://s.kitazaki.name/docs/geojson-spec-ja.html#g ...
↑こんな感じでオブジェクトを書いていきます。
ブラウザ上ではラスタタイルとほぼ同じように表示されます。 国土地理院がベクタタイルの提供実験を行っているのでリンクを貼っておきます。
http://gsi-cyberjapan.github.io/vector-tile-experiment/#16/35.7057/139.9575
ベクタタイルを用いるとブラウザ上でオブジェクトとして使うことが出来るため、対象をクリックして詳細を表示といったことをすることが出来ます。一方、ベクタタイルはブラウザ上でオブジェクトとして表示するためラスタタイルで表示するのに比べて重くなりがちです。特に表示するオブジェクトが多いとスムーズにスクロール出来なかったりします。そういった場合はポリゴンの頂点を元データより削減して圧縮表示をする場合があります。(Google Map等)
空間参照系
GIS系のデータを扱うときに度々必要になるのが、空間参照系の指定です。
地球全体をどんな回転楕円体として近似させるか決定するパラメータ、回転体を平面で表示するときの投影方法などをまとめた規格があり、空間参照系といいます。
空間参照系は地域ごとに異なったパラメータを用いたりもするので、組み合わせが沢山あります。
Spatial Reference List -- Spatial Reference
そこまで高い精度を用いる必要がない場合は地球全体の形に近似した楕円体のWGS84という空間参照系を使うことが多いです。実際にGPSの座標計算や多くの地図表示アプリ(Google Mapとか)ではWGS84を用いています。
二点間の距離を求める公式
地球を回転楕円体としてみなすため、二点間の距離も楕円体に沿った距離を計算する必要があります。
緯度経度から二点間の距離を計算するためのヒュベニの公式というものがあり、実際にその計算方法をJavaScriptのコードにしたものを下に示します。
GISデータをデータベースに格納
ベクタタイル等で使うポリゴンや位置情報はgeometry型という型が便利です。
点・線・図形などのオブジェクトや空間参照系など地理情報に関わるデータを一つのカラムにまとめて表現することが出来ます。
また、集約関数などもあり、図形同士の結合、分割や凸包とかを処理するための関数もあります。
MySQLでは標準でgeometry型が実装されていて、PostgreSQLではPostGISという拡張機能によって実装されています。
僕の場合はPostGISしか使ったことがないので断言はできませんが、リファレンス等を読むと機能的な差異はそこまでないと思います。
あとがき
バイトでは知らなくて書き直したことが結構あって(GeoJSONとか知らなくて独自フォーマットで実装したりした。 ちゃんと調べていれば良かったのになということが多々ありました。 地図を表示するのはGeoJSONとか地図タイルとか便利なものを知っていると結構簡単に作ることができて、最近のスマホではJavaScriptでGPSの座標とかも取得できるので知っているだけで結構面白いものが作れます。 ちょっと作ってみたいものとしてはサイクリスト向けの位置情報共有サイトとかどうですかね。kstmは体育会系のサークルなのでラーメン食べるために自転車で山を越えることもあるそうですが、一緒に走っていた人が見えなくなった時に開くと位置情報で場所がわかるみたいな。道路情報や距離計算などを組み合わせてカーナビを作るということも夢ではないかもしれません。
pixiv夏インターンに参加しました
ssl.pixiv.net ↑コレ
参加するまで
7月に選考のエントリーがあり、Skype面接を経て通りました。(初めてコーディング面接とかやった笑) 昔からpixivは知っていて、中学のころは周りに絵描きの人が多かったので自分も使っていたことがあります。私には絵の才能はなさそうですが、絵を見るのは割と好きだったりします。
インターンに参加したのは先輩に「なんかインターンしてみたいんですよね」って言ったときにWeb系ならpixivがいいんじゃないと言われ応募してみました。
面接について
私はGitHub選考でエントリーして(ただGitHubのURLを書くだけで、意気込みとかを書く欄すらなかった)、選考を通過したのちSkype面接がありました。Skype面接は主に今どんなことをしているかとか、どんなものを作ったことがあるか、あとオンラインエディタで実際にコーディングしてみるとかもありました。面接の方はエンジニアの方で、1時間ほど楽しく面接しました。 コーディング内容はそんなに難しくなく、競技プログラマーならそんなに考えなくても解けるだろうというレベルでした(AtCoderで言うとABCのB問かC問ぐらいのレベル)
実際にインターンに参加してみて
当日は京都の実家から新幹線に乗って直接pixivオフィスに向かいました。実は新幹線一本乗り過ごしてむっちゃ焦ってた。
pixivのオフィスは代々木駅から歩いて10分のビルの2階で一つのフロア丸々pixivのオフィスになっていました。 今回のインターンは実際にそれぞれのチームに配属して現状の課題にチームと一緒に取り組んでいくという内容でした。(まさに職業体験) 私が配属されたのはpixiv Sketchというお絵かき版Twitterみたいなサービスで、投稿した絵がタイムラインを流れていくSNSを開発するチームです。十数人ほどのチームで(pixiv全体は100人ぐらいいる)与えられた仕事はタグのページをもっとモチベーションの上がるようなページにするというタスクでした。
Sketchのフロントエンドは自分があんまり触ったことのないReactやFluxibleが使われていて、大変苦労しました。メンターさんに教えてもらいながら二つページがあるうちの一つは大体完成したという感じでした。
他の人の話を聞いて
今回のインターンでなかなか自分が関わることのなさそうな人(特に総合職インターンや人事の方など)と話をしてみてもっといろんな人と話をしてみたいなと思いました。例えば、今回のインターンは技術職と総合職に分かれて選考が行われましたが、5日目にインターン生の成果発表があり、総合職の方の発表を聞いていてそういう働き方もあるのかと自分の中では驚きがたくさんありました。総合職インターンの仕事ではプレミアムプランへの勧誘メール送信・特集記事の投稿・アプリ版への勧誘ポップアップをどう表示するかなど数値を使いながら具体的に試行錯誤していたようです。自分の中ではエンジニア以外の仕事がどういったものなのか知る機会はすごく珍しいのでとても良い機会になりました。
くやしいこと
インターンに来て開発環境構築に二日丸々使ってしまうという情弱っぷりを見せてしまって実質コード書いた時間が1日しかなかったので、全部完成させるのは厳しかった・・・ 人類にDockerは早すぎた
もっと真面目な話
インターン参加していてなんでpixivはここまで至れり尽くせりなのかすごく疑問でした。 飲み物飲み放題で宿泊費と交通費・昼食もタダだったのでインターン生の人数を考えるとうん百万近くは飛んでそう・・・と思うのですが、実際に同じチームで作業しているとpixivの方はとても自社サービス愛を感じました。会社というのは常に利益を追い求めなければいけないものではあるのですが、pixivの場合の利益というのは結局のところどれだけユーザーに使ってもらえるかというところに帰着するのでユーザーの使いやすさ等を考慮して議論して積極的に改善しているのが伺えました。インターンはその一環として、pixivをより良いものにするための仲間集めにすぎないようです。
pixivにとってインターンは社員の方の雰囲気とインターン生が合うかどうかを試す場所のようです。お見合いみたいなものかな。自分も大学のサークルみたいな雰囲気ですごく居心地のいい所だと思いましたし、こういう所で働きたいと思いました。(僕自身があんまり積極的でなかったのはよくない)ただ、pixivの雰囲気がここまで良いのはただの偶然ではなさそうです。今では100人規模の会社ですが、昔からこの雰囲気は受け継がれていて、社員の方の中にもこの雰囲気を崩したくないという思いがあるようです。なので、自分に合うか合わないかはインターンに行ってみて決めればいいと思います。
その他
業務中にGo言語君の顔をしたピカチュウが流れてきて不意打ちを打たれた
最後に
インターン中はたくさんの方にお世話になりました。メンターの@geta6さんをはじめチームの方や他のインターン生、人事の方などからいろんな話を聞けて自分がどういう働き方をしたいか考えるきっかけになりました。5日間と短い間でしたが、いろんな経験をさせていただきありがとうございました。お世話になりました。
むっちゃ楽しそう
むっちゃ楽しそうやんけ!って思ったそこのあなた。インターンに応募しましょう。